目录
背景
亮点
环境配置
数据
方法
结果
代码获取
参考文献
背景
人类大约花三分之一的时间睡觉,这使得监视睡眠成为幸福感的组成部分。 在本文中,提出了用于端到端睡眠阶段的34层深残留的Convnet架构
亮点
使用深度1D CNN残差架构,用于端到端分类, 可以解决训练更深的CNN模型引起的消失梯度问题。
环境配置
python; tensorflow
数据
Sleep-EDF
方法
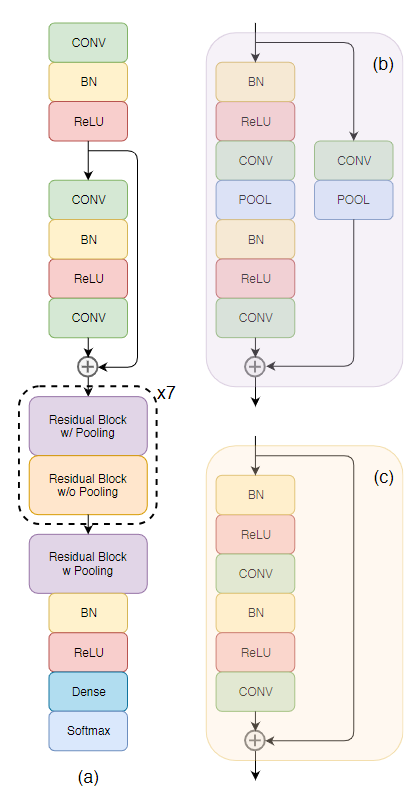
主要代码:
def res_first(input_tensor, filters=(64,64), kernel_size=16, dropout_rate=0.2, bias=False, maxnorm=4., **kwargs):
eps = 1.1e-5
nb_filter1, nb_filter2 = filters
x = Conv1D(filters=nb_filter1, kernel_initializer=initializers.he_normal(seed=1), kernel_size=kernel_size,
padding='same', use_bias=bias, kernel_constraint=max_norm(maxnorm))(input_tensor) ##
x = BatchNormalization(epsilon=eps, axis=-1)(x)
x = Scale(axis=-1)(x)
x = Activation('relu')(x)
x = Dropout(rate=dropout_rate, seed=1)(x)
x = Conv1D(filters=nb_filter2, kernel_initializer=initializers.he_normal(seed=1), kernel_size=kernel_size,
padding='same', use_bias=bias, kernel_constraint=max_norm(maxnorm))(x) ##
x = add([x, input_tensor])
return x
def MyModel(eeg_length=3000, kernel_size=16, bias=False, maxnorm=4., **kwargs):
'''
Top model for the CNN
Add details of module in docstring
'''
eps = 1.1e-5
#inputs = K.placeholder(shape=(batch_size, eeg_length,1))
#x = Input(dtype= 'float32', shape=(eeg_length,1))
EEG_input = Input(shape=(eeg_length,1))
x = Conv1D(filters=64, kernel_size=kernel_size, kernel_initializer=initializers.he_normal(seed=1), padding='same',
use_bias=bias, kernel_constraint=max_norm(maxnorm))(EEG_input) ##
x = BatchNormalization(epsilon=eps, axis=-1)(x)
x = Scale(axis=-1)(x)
x = Activation('relu')(x) #
x = res_first(x, filters=[64, 64], kernel_size=kernel_size)
x = res_subsam(x, filters=[64, 64], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[64, 64], kernel_size=kernel_size)
x = res_subsam(x, filters=[64, 128], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[128, 128], kernel_size=kernel_size)
x = res_subsam(x, filters=[128, 128], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[128, 128], kernel_size=kernel_size)
x = res_subsam(x, filters=[128, 192], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[192, 192], kernel_size=kernel_size)
x = res_subsam(x, filters=[192, 192], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[192, 192], kernel_size=kernel_size)
x = res_subsam(x, filters=[192, 256], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[256, 256], kernel_size=kernel_size)
x = res_subsam(x, filters=[256, 256], kernel_size=kernel_size, subsam=2)
x = res_nosub(x, filters=[256, 256], kernel_size=kernel_size)
x = res_subsam(x, filters=[256, 512], kernel_size=kernel_size, subsam=2)
x = BatchNormalization(epsilon=eps, axis=-1)(x)
x = Scale(axis=-1)(x)
x = Activation('relu')(x)
x = Model(EEG_input,x)
# tf.keras.backend.eval(x)
return x
结果
所有被试数据按照7:3的比例划分为训练和测试集数据,在单个被试在5分类的任务上,准确率达到91.4%,在6分类任务上,准确率达到90.1%。
![]()
代码获取
私信后台 S2
参考文献
L. Cen, Z. L. Yu, Y. Tang, W. Shi, T. Kluge, and W. Ser, “Deep learning method for sleep stage classification,” inInt. Conf. Neural Information Processing, 2017, pp. 796–802
M. Mourtazaev, B. Kemp, A. Zwinderman, and H. Kamphuisen, “Age and gender affect different characteristics of slow waves in the sleep eeg,”Sleep, vol. 18, no. 7, pp. 557–564, 1995.
K. He, X. Zhang, S. Ren, and J. Sun, “Identity mappings in deep residual networks,” inProc. ECCV, 2016, pp. 630–645.